Web scraping is a method of automatically gathering data from websites in a structured manner and storing it into a local database or spreadsheet. Why would you do this? Because you're lazy. Or because it's really impossible to copy-paste all the data you need from the website.
Some popular use-cases of web scraping are price comparison sites of products from different companies, lead generation from collected contact information, trend analysis of popular topics in a certain location. I simply wanted to see what are the most popular movies of 2018 and what features they have.
There are many tools for web scraping: browser plug-ins (e.g., Webscraper) and software (e.g., Parsehub) are easy to use and don't require coding.
However, if you need more advanced scraping settings and have basic coding skills, I recommend the Python libraries Beautiful Soup or Selenium, and the R package rvest. The latter is the one I used for scraping IMDb, and you can find the commented code on my GitHub.
Before I proceed to the fun part, note that the legality of web scraping is not clearly defined around the world, so you should check the website's terms of use before scraping it!
Now let's dive in. I wanted my data analysis to answer three questions:
- What are the most successful movies released in 2018?
- What genres do the popular movies belong to?
- What is the duration of the most popular movies?
Top popular movies
I used IMDb as a reference, because it contains all the information I need. On the website I selected the movies released between 01.01.-31.12.2018, sorted by popularity, and limited my search to the first page, so the top 50 movies.
library(rvest)
url <- "https://www.imdb.com/search/title?year=2018"
imdb <- read_html(url)
head(imdb)
The top 5 popular movies in 2018 were:
- Aquaman
- Green Book
- Bohemian Rhapsody
- Spider-Man: Into the Spider-Verse
- Avengers: Infinity War
Top movie genres
Scraping the genre tags of each movie is pretty straightforward:
genre_data_html <- html_nodes(imdb, ".genre")
genre_data <- html_text(genre_data_html)
head(genre_data)
However, this returns a list of genres for each movie, because the movies are labeled with multiple genres. The text data needs to be cleaned a bit:
#remove the \n in front of the genres
genre_data <- gsub("\n", "", genre_data)
#remove the spaces between genres
genre_data <- gsub(" ", "", genre_data)
Now, another tricky thing is that the genres of each movie are enumerated alphabetically, not in order of importance. To simplify my work, I selected only the first genre:
#display only the first genre in the list
genre_data <- gsub(",.*", "", genre_data)
At a glance, I noticed that 3 out 5 are action-hero movies, so I visualized closer at the genre distribution:
#plot the number of movies by genre
library(ggplot2)
ggplot(imdb_df, aes(x=genre_data)) +
geom_bar(color="purple", fill="green", alpha=0.3) +
ggtitle("Number of movies by genre") +
xlab("Genre") + ylab("Number of movies")
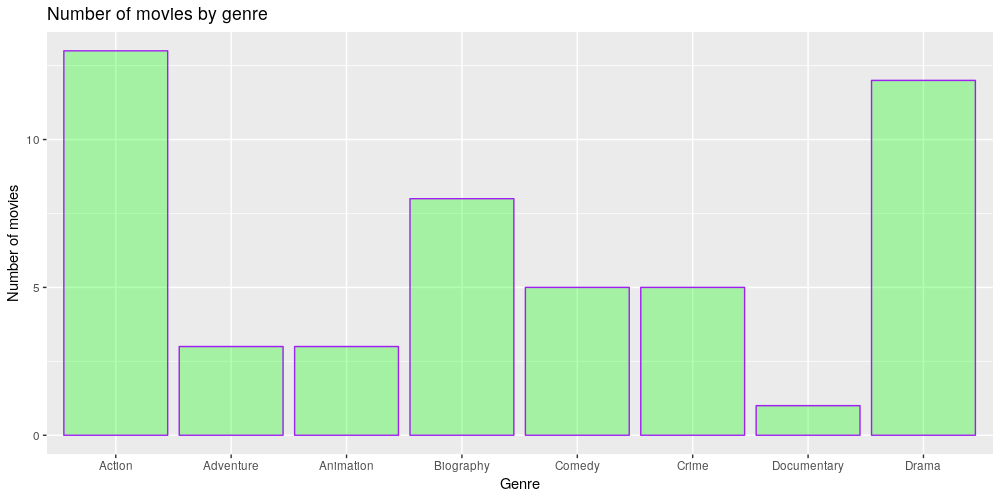
My initial observation was confirmed: Action and Drama are the most popular genres, followed by Biography. I guess most people enjoy, on one hand, movies that transport them into wild worlds and simulate experiences out of the ordinary, and on the other hand, movies that depict dramatic life stories and relate to some extent to their real life.
Top movies duration
Next, I analyzed the distribution of movie duration:
#plot the movies by runtime
barplot(table(imdb_df$Runtime))
hist(imdb_df$Runtime)
ggplot(imdb_df, aes(x=runtime_data)) +
geom_histogram(color="purple", fill="green", alpha=0.3) +
ggtitle("Distribution of movie runtimes") +
xlab("Minutes") + ylab("Number of movies")
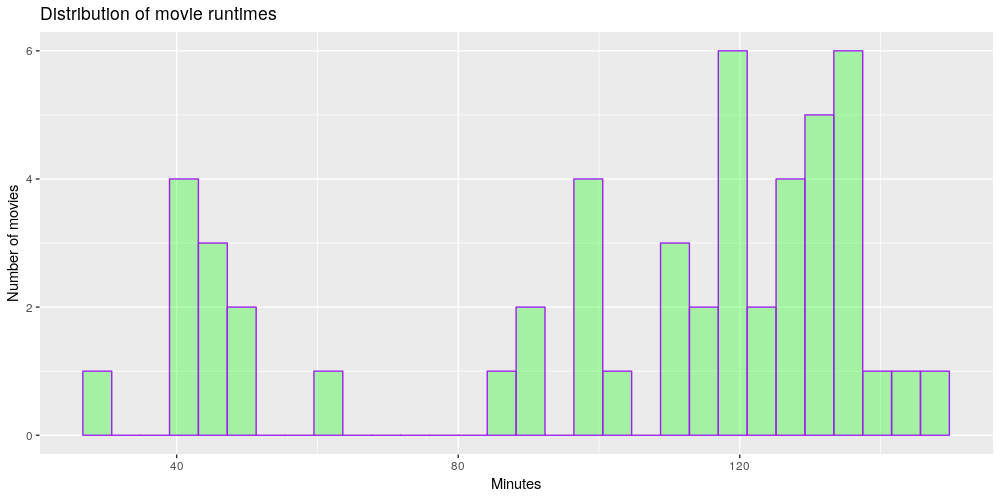
The plot shows that most popular movies last on average 104 minutes (median 117 minutes). The longest movie is Avengers: Infinity War (149 minutes) and the shortest movie (excluding TV-shows) is A.I. Rising (85 minutes). From the histogram it is clear that the bars on the left represent the TV-shows (under 60 minutes).
I also analyzed the runtime distribution by genre. First, I aggregated the movies by genre:
#group movies by genre
library(dplyr)
genre_cat = group_by(imdb_df, Genre)
genre_runtime = summarize(genre_cat, Minutes=mean(Runtime))
plot(genre_runtime)
Then, I visualized the average duration for each genre:
counts = table(genre_runtime$Genre, genre_runtime$Minutes)
ggplot(data=genre_runtime, aes(x=Genre, y=Minutes)) +
geom_bar(stat = "identity", color="purple", fill="green", alpha=0.3) +
ggtitle("Mean movie duration by genre")
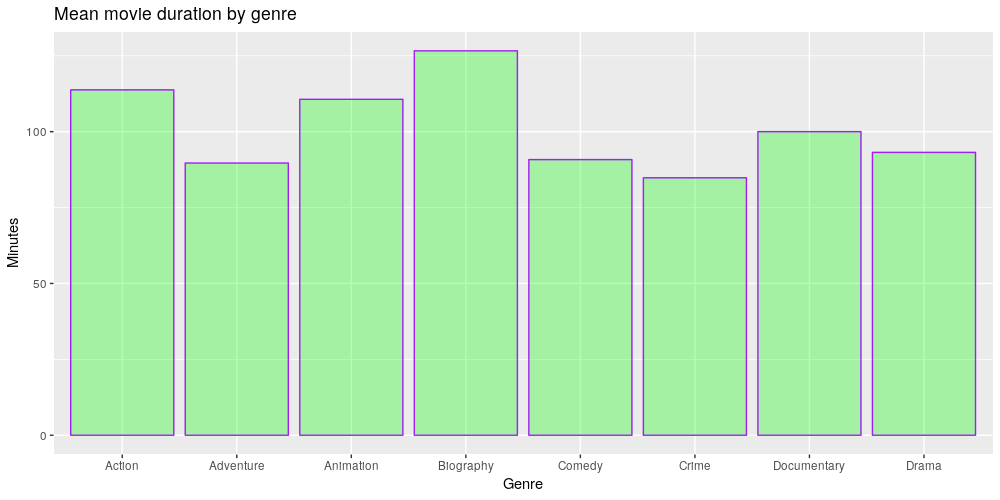
I found that among genres Biographies are longest (on average 127 minutes) and Crimes are shortest (on average 85 minutes).
This is not entirely surprising, since I think that, first, it is quite a challenge to pack a lifetime in a biographical movie, and second, there's only so much nerve-wrecking tension a person can take following a crime.
However, I was expecting the average duration of Animations to be shorter than 110 minutes, because they are produced mainly for children, who have a short attention span and low patience to sit through a two-hour movie. But then again, we are talking about the most popular movies of last year on IMDb, which means that adults made up the large audience.
Conclusion
This is a simple web scraping project that can reveal a lot of information about people's movie preferences. It would be interesting to also analyze the total gross and see which movies and genres have sold best in 2018. Now you could try to scrape and analyze this information with your preferred tool and let me know what you found out!
With all this in mind, I'm heading to watch the 36th movie and only documentary in IMDb's Top 2018: Free Solo. Some realistic action and drama, for once.